先日、コマンドライン上で DeepL API を利用できるツール&ライブラリである「dptran」の v2.1.0 を公開しました。
dptran - crates.io: Rust Package Registry
近頃、開発日記的なものを一切書いていなかったので、たまには書いこうかなと思います。
既存機能(〜 ver.2.0.0)
そもそも dptran の開発日記を全然書いていなかったので、従来バージョンにはどんな機能があったのか?を先に示します。
- コマンドライン引数からのテキスト翻訳
- テキストを対話形式で翻訳(intractive mode)
- 複数行を翻訳
- パイプラインからテキスト翻訳
- 残りの DeepL API の翻訳可能文字数を確認
- DeepL API の言語コード一覧の取得
- Rust ライブラリとしての利用 (v2.0.0-)
DeepL API では、言語コード(Language code)を指定して翻訳先/翻訳元言語を設定します。日本語なら JA、英語なら EN-US / EN-GB などです。ただし、翻訳元言語については未指定のままでも翻訳でき、その場合は翻訳元が自動で検知されます。
dptran の従来バージョンでは、翻訳元文章の入力インターフェイスとしてコマンドライン引数、対話形式、パイプライン入力の3つを備えています。
コマンドライン引数はこんな感じ。
$ dptran "Hello!" -t JA
こんにちは
対して、対話形式は起動後にプロンプトが起動し、入力文が逐一翻訳されていきます。
$ dptran
> ありがとうございます。
Thank you very much.
> Ich stehe jeden Tag um 7 Uhr auf.
I get up at 7 a.m. every day.
> La reunión comienza a las 10 a.m.
The meeting begins at 10 a.m.
> 今天玩儿得真开心!
Had a great time today!
> quit
パイプライン入力では、別のコマンドからの入力を翻訳することが可能です。
$ man ls | head -10 | dptran -t JA
LS(1) ユーザーコマンド LS(1)
名前
ls - ディレクトリの内容を一覧表示する
シノプシス
ls [OPTION]...[ファイル]...
説明
FILE (デフォルトではカレントディレクトリ) に関する情報を一覧表示します。 cftuvSUX のいずれでもない場合は、エントリをアルファベット順に並べ替えます。
また、v2.0.0 からは library crate を用意しており、dptran の機能がライブラリとして、別の Rust アプリケーションでも利用可能になりました。library crate を利用すれば、dptran と同等以上のアプリケーションが作成できます。
[dependencies]
dptran = { default-features = false }
新機能(v2.1.0)
ここからは先日リリースした v2.1.0 の話です。上記の既存機能に加え、さらに以下の機能を実装しました。
- ファイルからテキスト翻訳
- エディタからテキスト翻訳
- 入力原文から改行を除去
- テキストファイルに翻訳結果を出力
- 翻訳結果のキャッシュ
目的別にカテゴライズすると「ファイル入出力への対応」「エディタからの入力への対応」「改行された文章を1行として翻訳」「翻訳回数の節約」といったところです。
ファイル入出力への対応
あらゆる ASCII ファイル(.txt、.md、etc.)から翻訳元文書を入力し、それを標準出力に表示 or ASCII ファイルとして保存できます。それぞれ入力元文書の指定は -i オプション、出力先文書の指定は -o オプションです。
例えば、今年の1月6日のこのブログのブログポストを英訳させてみるとこんな感じになります。
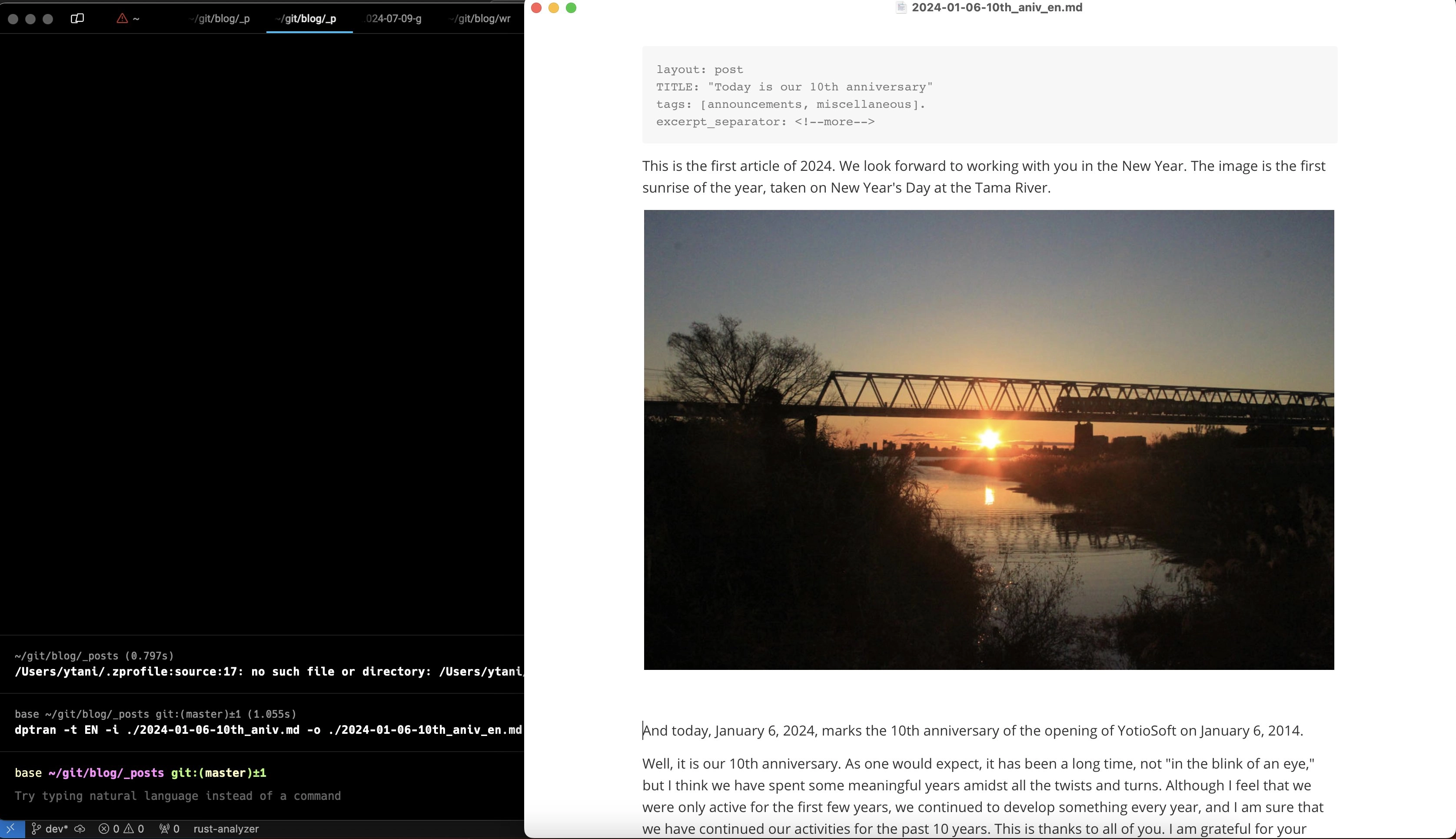
開発のエピソードとしては、ただ単にファイルストリームでファイルを読み込んで、翻訳元文書を API に渡して、翻訳先文書に書き出し…という操作ですので、それほど特筆すべき点はありません。
難点としては、たまに MarkDown や HTML などのタグを含むような文書を入力したとき、そのタグまで翻訳されてしまう点や、ASCII ではないファイル(例えば Word 文書や PDF など)には対応できない点かなと思います。そのあたりについては今後対応していきたいところです。
エディタからの入力への対応
翻訳元の文章を翻訳前に整形しなければならないとき、従来の dptran では一旦翻訳元文書から文章を何らかのエディタにコピペして、それを整形したうえで貼り付けなければなりません。これを dptran で完結させるにはエディタが必要です。しかし、自分には使い勝手の良いエディタを自作するほどの技術力もセンスもありません。
そこで git コマンドと同じように、お好みの CUI/GUI エディタ(vi、vim、emacs、nano など)から翻訳元文書を入力できるようにしました。
dptran のエディタ入力モード、出来てきたぞ pic.twitter.com/3XJbl49HRL
— yotio (@yotiosoft) June 19, 2024
仕組みとしては、翻訳元文章の記録用の一時ファイルを confy で用意した設定ファイルと同じディレクトリ内に作っておき、逐一各エディタからそこに書き込む、といった形を取ります。以降はファイルからの翻訳と同じ仕組みです。
エディタの起動には Command::new() を利用しています。仕組みとしては vim、vi、nano、emacs -nw といった、各エディタを起動するコマンドを設定ファイルに記録しておき、それに一時ファイルにファイルパスを追記して起動する、といった形です。
// Parse the editor command and the arguments
// e.g., "emacs -nw" -> "emacs", "-nw"
let mut editor_args = editor.split_whitespace();
let editor = editor_args.next().unwrap();
let editor_args = editor_args.collect::<Vec<&str>>().join(" ");
// Get tmp file path
let config_filepath = configure::get_config_file_path().map_err(|e| RuntimeError::ConfigError(e))?;
let tmp_filepath = config_filepath.parent().unwrap().join("tmp.txt");
// Open by the editor
let mut child = if editor_args.len() > 0 {
Command::new(editor).arg(editor_args).arg(tmp_filepath.to_str().unwrap()).spawn().map_err(|e| RuntimeError::EditorError(e.to_string()))?
}
else {
Command::new(editor).arg(tmp_filepath.to_str().unwrap()).spawn().map_err(|e| RuntimeError::EditorError(e.to_string()))?
};
let status = child.wait().map_err(|e| RuntimeError::EditorError(e.to_string()))?;
if !status.success() {
return Err(RuntimeError::EditorError("Editor failed".to_string()));
}
// Read from the tmp file
let text = std::fs::read_to_string(&tmp_filepath).map_err(|e| RuntimeError::FileIoError(e.to_string()))?;
なお、Emacs だけ emacs -nw としているのは、-nw オプションを追記しないと GUI で立ち上がってしまうためです。GUI で起動しても問題ないなら良いのですが、CUI だけで完結する手軽さが失われてしまいます。
苦労した点としては、emacs -nw のように引数を伴う場合に、それをコマンドと分離して指定しなければならない点。Command::new() では new() にコマンドを、arg() に引数のリストを指定しなければなりませんので、-nw は arg() の方に渡さなければなりません。
改行された文章を1行として翻訳
remove-line-breaks の略で -r オプション。これは主に、ウェブページ上の文章や PDF 文書などにありがちな、一つの文章に改行コードが含まれてしまう文章を一文にまとめて翻訳するための機能です。
例えば、下記の文章は途中で改行コードが入っていますので、このまま翻訳するとおかしな文章になってしまいます。
あなたとJAVA,
今すぐダウンロー
ド
You and JAVA,.
DOWNLOAD NOW
ド
-r オプションを使えば、下記のようにきれいな一文にまとめて翻訳できます。
あなたとJAVA,今すぐダウンロード
You and JAVA, DOWNLOAD NOW!
仕組みとしては、単純に改行コードを半角空白に置き換えているだけです。
if rm_line_breaks {
// Remove line breaks
let text = text.lines().collect::<Vec<&str>>().join(" ");
Some(vec![text])
}
(vec![text] が DeepL API に送信される)
翻訳結果のキャッシュ
同じ翻訳元言語から同じ翻訳先言語へ、同じ文章を何度も翻訳するのは無駄です。DeepL API は有料プランでは翻訳文字数が無制限ですが、無料プランでは月50万文字が上限となっています。
そこで、設定ファイルと同じディレクトリ内にキャッシュファイルを用意し、一度翻訳した文章はローカル環境でキャッシュするように変更しました。
例えば、こんな感じで翻訳していった場合。
$ dptran -t JA Hello!
こんにちは!
$ dptran -t JA How are you?
お元気ですか?
キャッシュファイルには下記のように toml 形式で翻訳結果が記録されていきます。
[elements.92be719734131eea3a661042dfa8b1b9]
key = '92be719734131eea3a661042dfa8b1b9'
target_langcode = 'JA'
value = 'こんにちは!'
[elements.ab1a795bacd63698547a40614d5109bc]
key = 'ab1a795bacd63698547a40614d5109bc'
target_langcode = 'JA'
value = 'お元気ですか?'
以降、$ dptran -t JA Hello! や $ dptran -t JA How are you? と再び翻訳したとき、dptran は DeepL API に問い合わせることなくキャッシュした結果を表示します。
// Check the cache
let cache_enabled = configure::get_cache_enabled().map_err(|e| RuntimeError::ConfigError(e))?;
let cache_str = input.clone().unwrap().join("\n").trim().to_string();
let cache_result = if cache_enabled {
cache::search_cache(&cache_str, &target_lang).map_err(|e| RuntimeError::CacheError(e))?
} else {
None
};
let translated_texts = if let Some(cached_text) = cache_result {
vec![cached_text]
// If not in cache, translate and store in cache
} else {
// translate
let result = dptran::translate(&api_key, input.clone().unwrap(), &target_lang, &source_lang)
.map_err(|e| RuntimeError::DeeplApiError(e))?;
// replace \" with "
let result = result.iter().map(|x| x.replace(r#"\""#, "\"")).collect::<Vec<String>>();
// store in cache
let max_entries = get_cache_max_entries()?;
if cache_enabled {
cache::into_cache_element(&cache_str, &result.clone().join("\n"), &target_lang, max_entries).map_err(|e| RuntimeError::FileIoError(e.to_string()))?;
}
result
};
この key の値が翻訳元文章を基に作成した md5 ハッシュ値にあたります。このハッシュ値をキーとし、翻訳時に既にキャッシュファイルに翻訳結果がキャッシュされていないかを先に検索します。もちろん、翻訳元・翻訳先言語が異なれば別のキャッシュとして扱います。
キャッシュの最大数はデフォルトで100個と定めています。最大キャッシュ数は $dptran cache -m <最大数> で変更できます。また、$ dptran set --disable-cache でキャッシュの無効化も可能です。
おわりに
当初から作りたかった機能はだいぶ完成してきました。まだまだ荒削りな部分はありますが、今後も改良を重ねてより使いやすいツール&使いやすいライブラリにしていけたらなと思います。