最近あまりにも書くネタがないので、過去に作った文書分類プログラムでも載せておこうと思います。
なお、筆者は自然言語処理は専門外ですので、中には間違った情報が含まれているかもしれません。ご了承ください。
実験環境など
-
Google Colaboratory
-
Python 3.10.12
-
numpy 1.23.5
-
scikit-learn 1.2.2
-
pandas 1.3.5
文書分類の仕組み
文書分類とは、複数からなる文書を何らかの基準に基づいてクラス分けするための操作です。BOW、出現回数ベクトル、TF-IDF などといったベクトル、あるいは重み付けを用いた手法があります。
BOW (Bag of Words)
BOW は単語をベクトルで表す手法の一つです。文書 j に対して、単語 i が出てきたら 1 、出てこなかったら 0 とします。
例:
-
文書1 : 私の名前は yotio です(W0 : 私 / W1 : の / W2 : 名前 / W3 : は / W4 : yotio / W5 : です)
-
文書2 : 私は魚が好きです(W0 : 私 / W3 : は / W6 : 魚 / W7 : が / W8 : 好き / W5 : です)
出現回数ベクトル
BOW とほぼ同様です。BOW では 0, 1 の2値だったのに対し、出現回数ベクトルでは出現回数のベクトルとします。
TF-IDF
TF-IDF は文書内に含まれる単語のうち、各単語がどれだけクラス分けの上で重要かという重み付けを行い、確率に基づいて文書分類を行います。
TF : Term Frequency
TF は各文書における単語の出現頻度を示し、次の式で表されます(n_{i.j} は単語 W_i が文書 d_j で出現するか回数)。
\[tf_{i,j}=\frac{n_{i,j}}{\sum_k n_{k,j}}\]IDF : Inverse Document Frequency
IDF は逆に、多数の文書に出現する単語の重要度を落とすための指標です。例えば「~が」「~に」「~を」「~へ」といった助詞は、どの文書にも出現する上に文書分類に役立ちません。よって、出現する文書数の逆数を求め、出現する文書が多いほど値が小さくなるようにします。
IDF は次の式で表されます(D は全体の文書数、d_{W_i} は単語 W_i が出てきた文書数)。
\[idf_{i,j}=\log{\frac{|D|}{|d_{W_i}|}}\]TF-IDF
最後に、これらを掛け合わせて重み付けを行います。単語 W_i に対する TF-IDF は
\[tfidf_{i,j}=tf_{i,j}idf_{i,j}\]で表されます。
機械学習
BOW および各単語の TF-IDF が求められたら、いよいよ機械学習を実行します。今回は以下の2つを使用するものとし、sklearn のライブラリ関数に任せます。
-
サポートベクターマシン (SVM)
-
ナイーブベイズ
データセット
今回は cls-acl10 というデータセットを用います。
Webis Cross-Lingual Sentiment Dataset 2010 (Webis-CLS-10) | Zenodo
これは 2010 年頃の Amazon レビューをまとめたもので、日本語や英語などのレビュー文書に対し、それぞれ高評価 / 低評価のラベル分けがなされています(よってポジネガ分析とも言えます)。さらに嬉しいことに、形態素解析済みの前処理済みデータセットもあり、こんな感じ↓で各文書における各単語の出現回数がデータ化されています。
は:13 が:13 に:11 て:11 で:10 。:10 の:9 を:8 と:6 作者:6 ます:5 か:5 ない:5 あずま:4
?:4 た:4 知ら:4 ん:4 知っ:4 <num>:3 思い:3 こと:3 、:3 てる:3 ので:3 :2 という:2 でし
ょ:2 資料:2 ネタ:2 作品:2 漫画:2 買っ:2 後半:2 ね:2 だ:2 つ:2 これ:2 し:2 う:2 い:2 分
かれ:2 読める:2 前半:2 その:2 的:2 評価:2 いる:2 です:2 でき:2 トリビュート:2 なので:1
数:1 ファン:1 選ぶ:1 ?阪:1 しかしながら:1 理解:1 買い:1 この:1 不満:1 ほとんど:1 な
ら:1 な:1 数多く:1 サッパリ:1 せ:1 ず:1 まし:1 純粋:1 ページ:1 き:1 ?分:1 記念:1 思え
る:1 グッズ:1 ?きく:1 多く:1 問題:1 絡ま:1 出:1 私的:1 おら:1 逆:1 かなり:1 ?:1 収
録:1 さん:1 他:1 様:1 周年:1 楽しん:1 も:1 半分:1 等:1 結果:1 なっ:1 れる:1 個?:1
?々:1 万博:1 どう:1 星:1 損:1 感じ:1 載っ:1 ?当て:1 ?っ:1 楽しむ:1 について:1 しま
い:1 しまう:1 #label#:positive
ちなみにこちらのレビュー文書の元データはこんな感じ↓です。
<item><category>本
</category><rating>4.0</rating><asin>4048680609</asin><url>http://www.amazon.co.jp/productreviews/4048680609/</url><text>あずまんが 10 周年記念で出たこの?阪万博。
前半はあずまんがグッズ等の資料が載っていて後半はトリビュート漫画です。
他の?々が?っておられる様に前半の資料についてはかなりの数を収録していて
あずまんがファンなら楽しんで読めると思います。
問題は後半で、これは作者とその作品を知っているかどうかで?きく評価が分かれますね。
私的にはほとんどが知ってる作者なのでそのネタを楽しむことができました。
しかしながら、作者を知らず純粋にあずまんが?当てで買った?には不満に思えるでしょう。
多くの作者さんが?分の作品のネタと絡ませてきているので知らない?にはサッパリだと思います。
なので作者を数多く知ってる?には買いだと思います。逆に知らない?は買っても理解できないので
結果的に読めるページが半分になってしまい、損をしたと感じてしまうのではないでしょうか。
ということで個?的には星 5 つですが?を選ぶということで 4 つで。</text><title>?阪万博
</title><summary>これはトリビュート漫画の作者を知ってるか知らないかで評価が分かれますね
</summary><date>2009/10/28</date><location
/><helpfulness_votes><value>93</value><value>83</value></helpfulness_votes><reviewer>陽?
</reviewer><badges /></item>
ラベルは前述の通り高評価 (poitive) と低評価 (negative) の2通りで、データセットは books, dvd, music の3つがあります。今回はそれぞれについて実行してみます。
今回行うこと
データセット cls-acl10 の学習データに含まれる各レビュー文書から BOW、出現回数ベクトル、TF-IDF のそれぞれを用いたクラス分けを SVM、ナイーブベイズで機械学習して、テストデータの分類を試みます。
実装
プログラム全体はこちらで公開しています。
document_classification.ipynb - Colaboratory
ファイルは下記のように配置しているものとします。
-
tfidf.py (今回実装する Python プログラム)
-
cls-acl10-processed (前処理済みデータセット)
-
jp
-
books
-
test.processed (前処理済みテスト用文書データ)
-
train.processed (前処理済み学習用文書データ)
-
-
dvd
-
music
-
-
ReviewClass
ReviewClass というものが今回実装したレビューデータ用クラスです。
機械学習は以下の流れで行います。
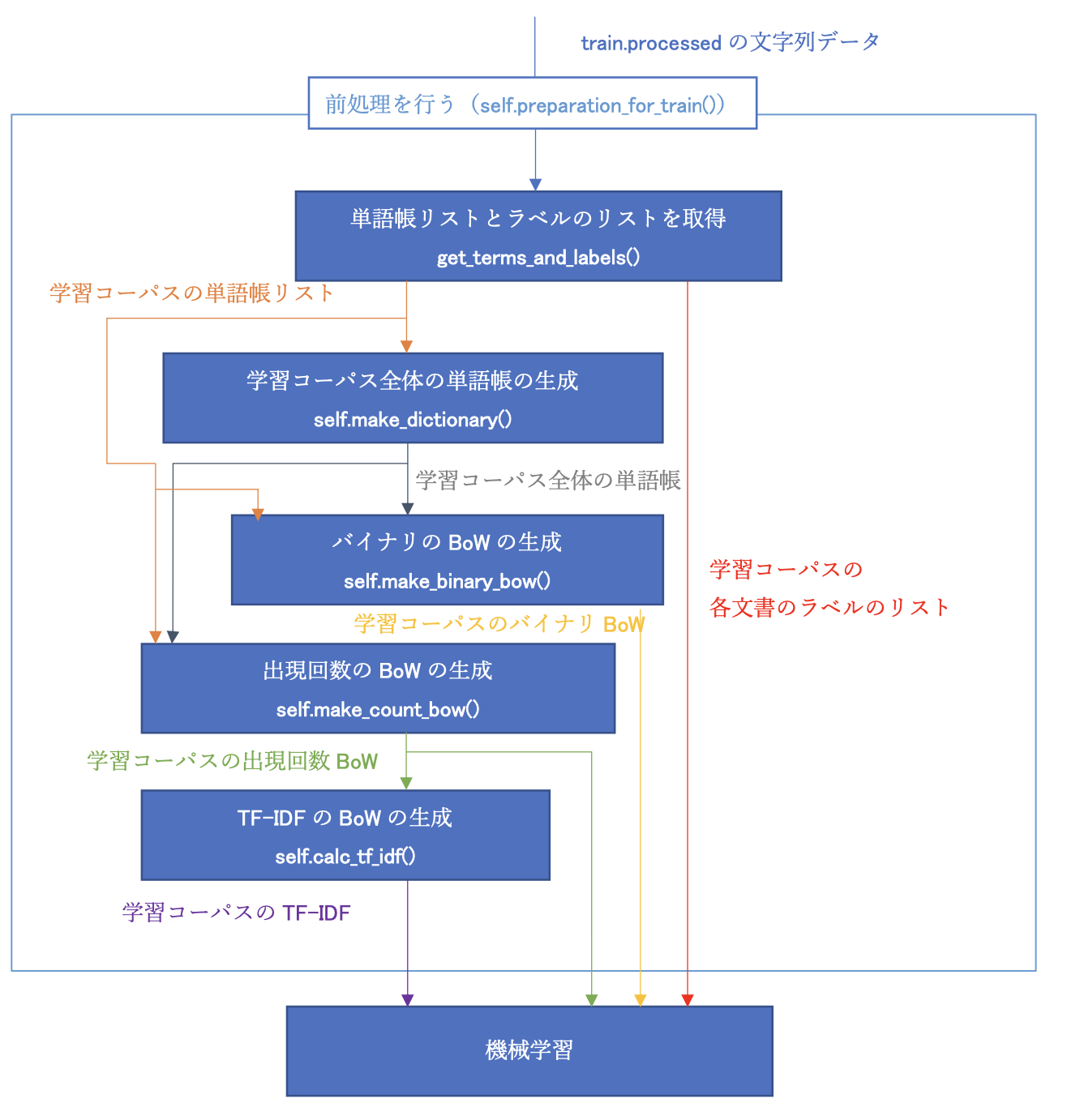
また、テストデータの文書分類はこんな感じで行います。
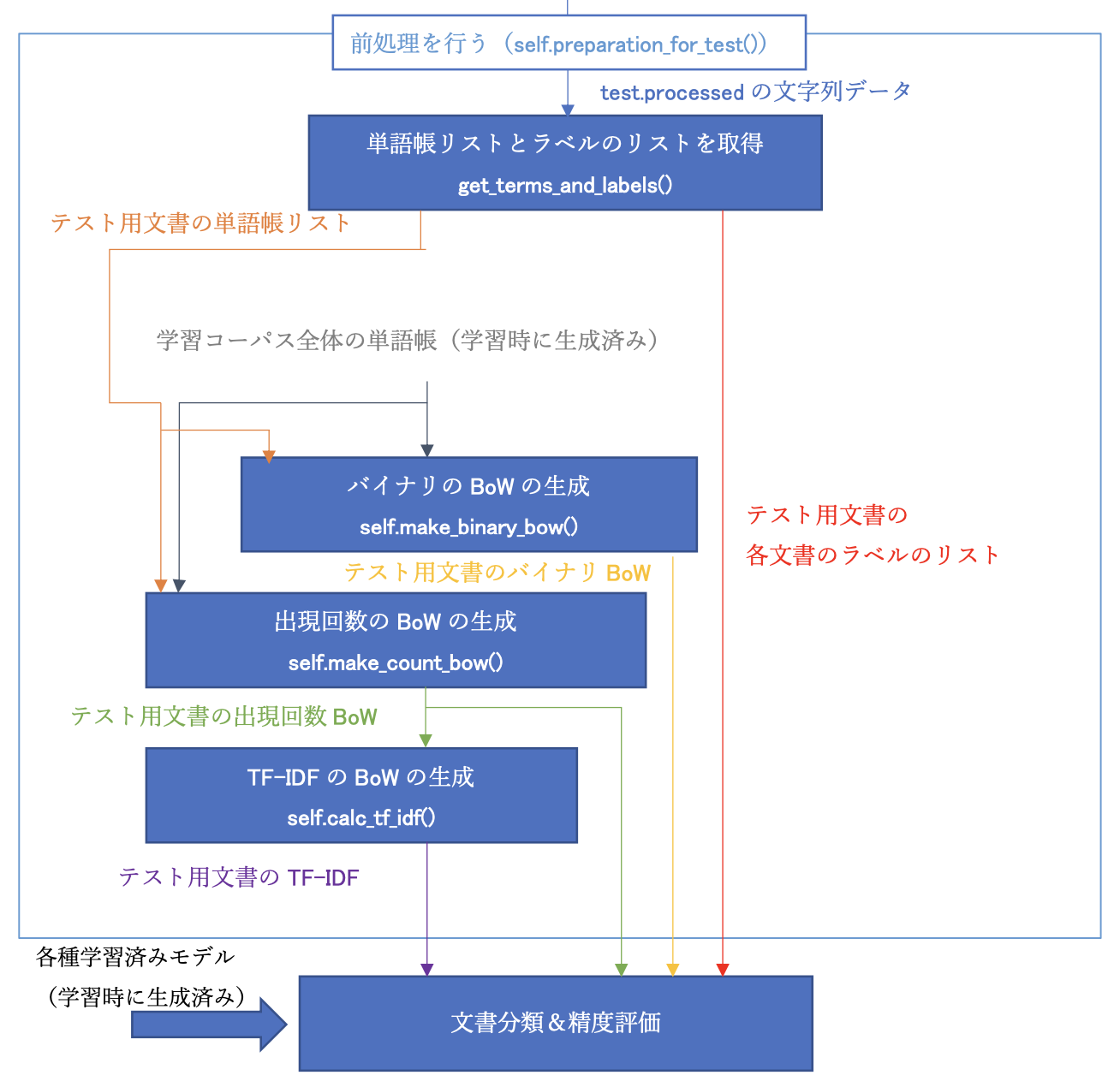
使用方法
ファイルを開いて ReviewClass に渡し、学習を実行するまでのコードは以下の通り。
# booksのレビューデータ
# 学習データ読み込み
train_processed_books = open('./cls-acl10-processed/jp/books/train.processed', 'r').read()
books = ReviewClass()
books.preparetion(train_processed_books)
# SVMで学習
books.svm_train()
# テストデータを読み込み
test_processed_books = open('./cls-acl10-processed/jp/books/test.processed', 'r').read()
books.preparation_for_test(test_processed_books)
# SVMで予測
books.predict_svm()
# ナイーブベイズモデルによる学習
books.nb_train()
# ナイーブベイズモデルによる予測
books.predict_nb()
get_terms_and_labels() : 単語の抽出
def get_terms_and_labels(processed_data):
# 文書ごとに切りわけ
# ※処理済みデータは1行で1文書
reviews = processed_data.split("\n")
# 単語を抽出する
review_terms_array = []
review_labels_array = []
for review in reviews:
# 空白行(処理済みデータの最終行)は無視
if len(review) == 0:
continue
# 各単語の抽出
review_label, review_terms = get_terms(review)
# review_terms_array, review_labels_arrayに格納
review_terms_array.append(review_terms)
review_labels_array.append(review_label)
return review_terms_array, review_labels_arrayview_dics[0].keys())
preparetion() : 前準備
各単語が各文書に含まれるかどうかを示す単語帳リストと、各単語がどちらのラベルに属するかを示すラベルリストをここで生成します。
# 学習前の準備
# 文書データの取り込みやTF-IDFの計算など
def preparetion(self, train_processed_data):
# 処理済みデータを各文書に対応する単語配列、ラベル配列に格納
print("単語とラベルの読み込み中…")
train_review_terms_array, self.train_review_labels_array = get_terms_and_labels(train_processed_data)
# 単語帳の生成
print("単語帳の生成中…")
self.dic = self.make_dictionary(train_review_terms_array)
さらに、BOW 、出現回数ベクトルの生成と TF-IDF の計算も行います。
# BOWの生成
# バイナリ素性値ベクトルの生成
print("バイナリ素性値ベクトルの生成中…")
self.train_binary_vector = self.calc_binary_vector(train_review_terms_array)
# 出現回数ベクトルの生成
print("出現回数ベクトルの生成中…")
self.train_count_vector = self.calc_count_vector(train_review_terms_array)
# 学習データのTF-IDFの計算(出現回数ベクトルを使用)
print("TF-IDFの計算中…")
self.train_tf_idf = self.calc_tf_idf(self.train_count_vector)
BOW の生成
def calc_binary_vector(self, review_terms_array):
# バイナリの素性値を生成
review_dics = []
for review_term in review_terms_array:
review_dic = self.dic.copy() # 上で生成した単語帳(出現回数はすべて0にリセット済み)をコピー
for review_term_key, review_term_count in review_term.items():
# 単語帳に存在する単語なら1をベクトルに記入
if review_term_key in review_dic:
review_dic[review_term_key] = 1
review_dics.append(review_dic)
# バイナリ素性値ベクトルのBOWの生成
bow_binary_vector = []
for review_dic in review_dics:
bow_binary_vector.append(list(review_dic.values()))
return bow_binary_vector
出現回数ベクトルの生成
def calc_count_vector(self, review_terms_array):
# 文書ごとに出現回数を書き込み
review_dics = []
for review_term in review_terms_array:
review_dic = self.dic.copy() # 上で生成した単語帳(出現回数はすべて0にリセット済み)をコピー
for review_term_key, review_term_count in review_term.items():
# 単語帳に存在する単語なら出現回数を代入
if review_term_key in review_dic:
review_dic[review_term_key] = review_term_count
review_dics.append(review_dic)
# 出現回数ベクトルを生成
bow_count_vector = []
for review_dic in review_dics:
bow_count_vector.append(list(review_dic.values()))
return bow_count_vector
TF-IDF の算出
上で偉そうに説明していましたが、今回は sklearn のライブラリ関数に頼っちゃいます。
def calc_tf_idf(self, count_vector):
# TF-IDFの計算
transformer = TfidfTransformer(smooth_idf = False)
tfidf_matrix = transformer.fit_transform(count_vector)
tf_idf = tfidf_matrix.toarray()
return tf_idf
SVM
ここも sklearn のライブラリ関数 fit_svm() を使用しています。
# SVMによる学習
def svm_train(self):
# SVMで学習
print("バイナリ素性値ベクトルを学習中…")
self.svm_binary_model = self.fit_svm(self.train_binary_vector, self.train_review_labels_array)
print("出現回数ベクトルを学習中…")
self.svm_count_model = self.fit_svm(self.train_count_vector, self.train_review_labels_array)
print("TF-IDFベクトルを学習中…")
self.svm_tfidf_model = self.fit_svm(self.train_tf_idf, self.train_review_labels_array)
print("完了.")
ナイーブベイズ
ここも以下略
# ナイーブベイズモデルによる学習
def nb_train(self):
# ナイーブベイズで学習
print("バイナリ素性値ベクトルを学習中…")
self.nb_binary_model = self.fit_nb(self.train_binary_vector, self.train_review_labels_array)
print("出現回数ベクトルベクトルを学習中…")
self.nb_count_model = self.fit_nb(self.train_count_vector, self.train_review_labels_array)
print("TF-IDFベクトルを学習中…")
self.nb_tfidf_model = self.fit_nb(self.train_tf_idf, self.train_review_labels_array)
print("完了.")
実験結果
まず、正解率がこちら。(バイナリが BOW、出現回数が出現回数ベクトル)
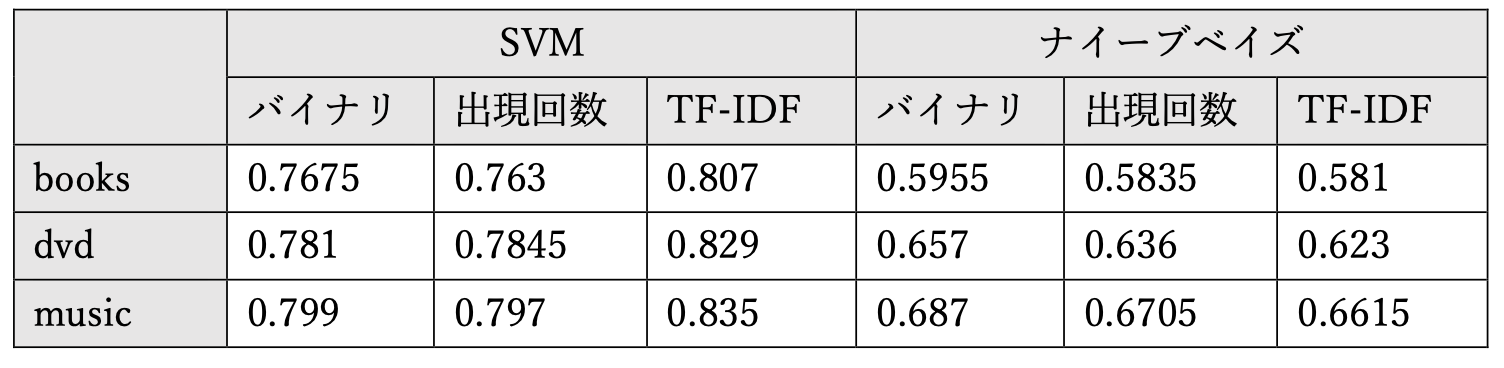
正解率は良くて8割程度で、いずれも TF-IDF & SVM が一番高い正解率でした。
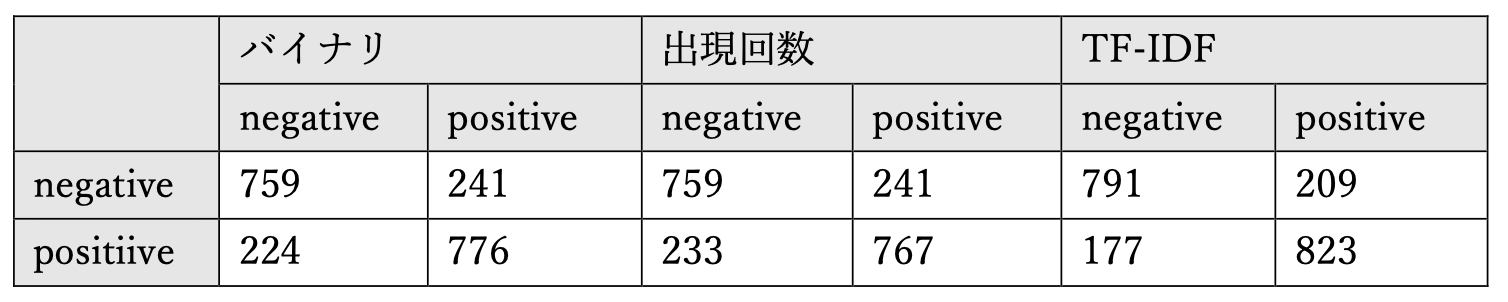
次に、混同行列がこちら。縦軸が実際のクラスで、横軸が分類結果のクラスです。
-
books - SVM
-
books - ナイーブベイズ

-
dvd - SVM
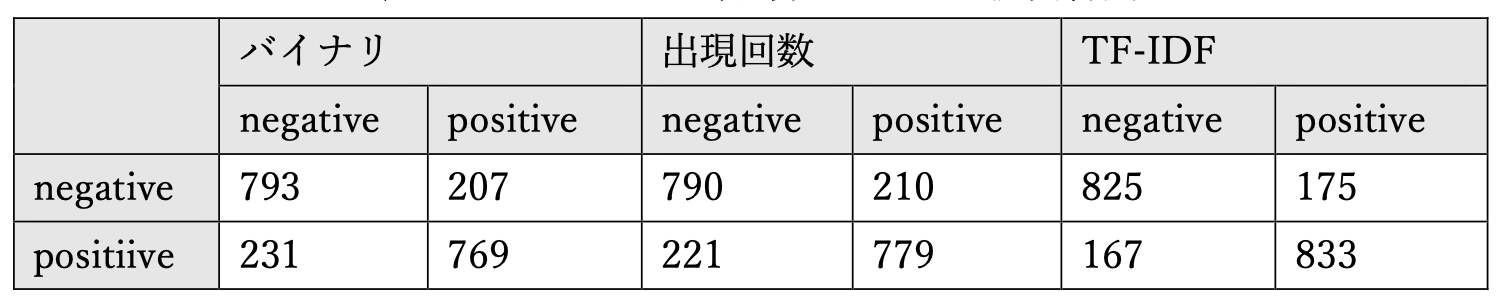
-
dvd - ナイーブベイズ

-
music - SVM

-
music - ナイーブベイズ

最後に、最も正解率が高かった TF-IDF での music において、どのような単語が重要な単語として重み付けされたか見てみます。
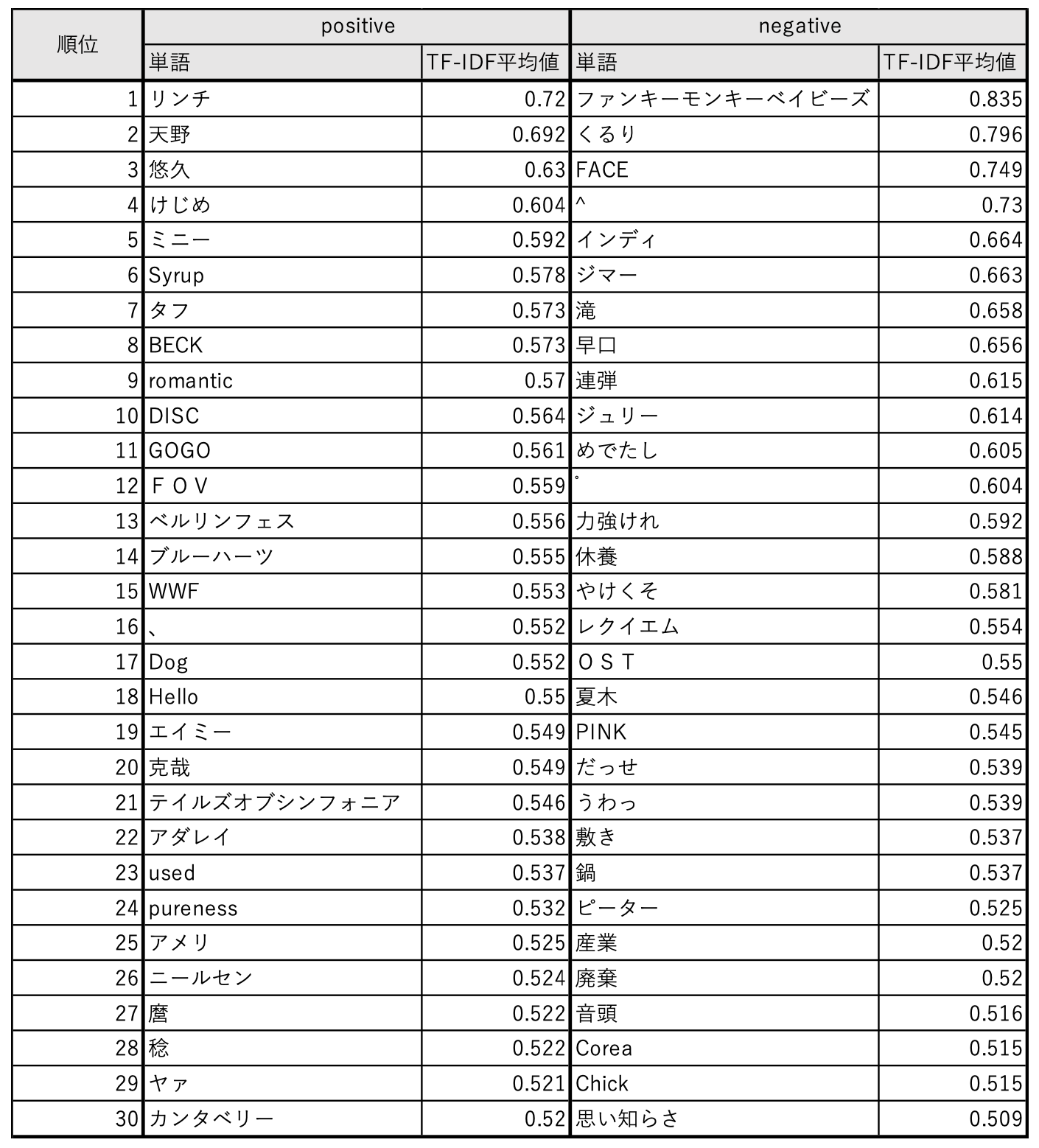
…これだけ見ても傾向は分かりませんね。
negative クラスには「うわっ」とか「だっせ」「やけくそ」「産業 - 廃棄」といった悪口ととれる単語が並んでいますが、多くは固有名詞です。商品によって大まかな評価が分かれているが故の結果な気もします。
次に、positive クラスに分類されたレビューを見てみます。
<item>
<category>ミュージック</category>
<rating>5.0</rating>
<asin>B00005USMT</asin>
<url>http://www.amazon.co.jp/product-reviews/B00005USMT/</url>
<text>フェリーが帰ってきた的悦びファンに与えまくり与えまくりな快作っす!
いきなりディランのカバーで幕開け、YRAH!原点お帰りフェリー!
でイキのいいバンドサウンドバックに久々締まり抜けまくりながらも微シャウトしておりまっす!
ハーモニカも久々使いまくりで味わい深さ5割増っす!
ハーモニカ、けっこうフェリーにはマストなアイテムなんすねぇ?ぇぇぃ・・・
カバーとオリジナルがちょうど半々の割合で傑作『ベールをぬいだ花嫁』を想起させまっす!あのアルバム同様、カバーの王様としてのフェリーと、
誰にも真似真似無理ぃーなポップなのに変これ変!な独自のセンスが光るソングライターとしての才能が両方堪能できまっす!
あとやっぱバックのメンバーチョイスうめぇっすわ・・・
イーノも参加っすが二人の共作「I Thought」はサイコッ!
フェリーにはないイーノの緩?さ活かしまくって、大人になった「Virginia Plain」みたくな
最高の緩モア?な和ませソング作ってくれました!最新作『ディラネスク』でもイーノ参加の曲
(「If Not For You」)は緩っ緩っしたねぇ?ぇぇぇぃ・・・
お互いの才能を活かしあえるくれぇ成熟な二人の再会もファンには嬉しいファン泣かせまくり
慟哭うぇぃなフェリー下手したらソロ、1,2を争う傑作っす!
フェリーサイコサイコサイコサイコサイコッ!!!!
YEAH!!!!
</text>
<title>フランティック</title>
<summary>星足んね足んね足んねっ!!</summary>
<date>2007/3/13</date>
<location>ALONE</location>
<helpfulness_votes>
<value>5</value>
<value>4</value>
</helpfulness_votes>
<reviewer>NICEMAN "ァヘァヘィヘィヘ"</reviewer>
<badges />
</item>
見るからにべた褒めしているレビューで、実際にデータセットでも positive クラスとして分類されています。
次に、実際には negative クラスに分類されたものがこちら。
<item>
<category>ミュージック </category>
<rating>1.0</rating>
<asin>B000063S0S</asin>
<url>http://www.amazon.co.jp/prod uct-reviews/B000063S0S/</url>
<text>うわっ!だっせぇ!</text>
<title>Yeah Yeah Yeahs [12 inch Analog]</title>
<summary>げ</summary>
<date>2002/10/3</date>
<location />
<helpfulness_votes>
<value>124</value>
<value>12</value>
</helpfulness_votes>
<reviewer>g oe</reviewer>
<badges />
</item>
ド直球ですね。「うわっ」も「だっせ」も TF-IDF において、negative クラスの上位にランクインしています。
おわりに
TF-IDF で 8 割程度の精度なら叩き出せることを確認しました。レビューに対する評価(役に立った / 立たなかった)などをパラメータに加えるともっと精度が良くなりそうですが、今回はお遊び程度なのでこれで良しとします。